Scrapy: Gotta scrape ′em all!
Dank dem Internet haben wir heute Zugang zu jeder erdenklichen Information und müssen diese nur noch über unseren Browser aufrufen. Doch letzteres wird schnell zum Problem, da die Auswahl so überwältigend sein kann. Aus dieser Not geboren, wurden Crawler und Scraper entwickelt, die das Internet durchforsten, relevante Informationen extrahieren und sammeln. Die so gewonnen Daten




Da es aber nicht für jeden Anwendungsfall eine entsprechende Suchmaschine gibt, möchte ich euch zeigen, wie ihr mit Python und Scrapy euren eigenen Scraper schreiben könnt.
Wähle deinen Starter!

Screenshot: Pokémon blaue Edition
$ pip install scrapy Mit Scrapy können wir uns beim Entwickeln auf das auf das wesentliche konzentrieren und mit wenig Code einen robusten Scraper schreiben. Dabei übernimmt Scrapy für uns das eigentliche Herunterladen der Seite, die Fehlerbehandlung, die Parallelisierung verschiedener Anfragen, die Begrenzung der gleichzeitig möglichen Anfragen und vieles mehr. Wir müssen nur noch angeben wo unser Scraper die von uns gewünschten Daten findet und wo sie gespeichert werden sollen.
Der Pokédex
Nachdem geklärt ist, warum wir Scrapy nutzen, ist es an der Zeit unseren ersten Scraper zu schreiben. Dazu erstellen wir die Datei scrapeThemAll.py, importieren verschiedene Scrapy Module und beschreiben die Informationen die wir auslesen möchten. In unserem Fall sind das natürlich Pokémon und konkret interessieren wir uns für den Namen, die Nummer im Pokédex, als auch den jeweiligen Typen und Schwächen. Deswegen legen wir als erstes eine Klasse Pokemon an, die von der Scrapy Klasse Item erbt, und definieren für jede Eigenschaft ein entsprechendes Feld:
from scrapy import Spider
from scrapy.item import Item, Field
from scrapy.crawler import CrawlerProcess
class Pokemon(Item):
name = Field()
number = Field()
type = Field()
weakness = Field()
evolution = Field()
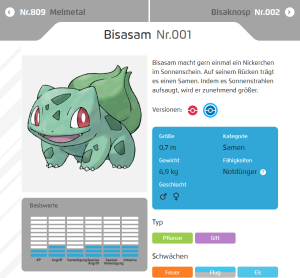
www.pokemon.com/de/pokedex/001
Danach können wir schon mit dem eigentlichen Scraper loslegen. Wieder nutzen wir eine Scrapy Klasse als Vorlage und definieren den Namen des Scrapers und einen Startpunkt. Da wir unseren eigenen Pokédex vervollständigen wollen, ist für uns der Ideale Startpunkt https://www.pokemon.com/de/pokedex/001, also der offizielle Pokédexeintrag von Bisasam. Auf dieser Seite erhalten wir alle relevanten Informationen zu Bisasam und finden auch einen Link zum nächsten Eintrag. Damit der Scraper weiß, wie er die heruntergeladenen Seite verarbeiten soll, überschreiben wir die Funktion parse. Diese Funktion wird für jede Seite einmal aufgerufen und sollte im Idealfall ein oder mehrere Scrapy Items erzeugen. In unserem Fall haben wir pro Seite genau ein Pokémon und können deswegen in der ersten Zeile, mit der Klasse Pokemon , unser Item initialisieren. Danach extrahieren wir aus dem HTML-Code, über die Funktion css, die für uns relevanten Daten. Besonders schön hierbei ist, dass die Funktion den eigenen Pseudoselektor ::text implementiert, über den man den Text direkt auswählen kann. Alternativ kann man man auch mit XPath-Selektoren arbeiten, jedoch bevorzuge ich ganz klar die gewohnten CSS-Selektoren.
class PokeSpider(Spider):
name = 'pokeSpider'
start_urls = [
'https://www.pokemon.com/de/pokedex/001',
]
def parse(self, response):
item = Pokemon()
item['name'] = response.css('.pokedex-pokemon-pagination-title div::text').get().strip()
item['number'] = response.css('.pokedex-pokemon-pagination-title .pokemon-number::text').get().strip()[3:]
item['type'] = []
item['weakness'] = []
for type in response.css('.pokedex-pokemon-attributes.active .dtm-type li'):
item['type'].append(type.css('a ::text').get())
for weakness in response.css('.pokedex-pokemon-attributes.active .dtm-weaknesses li'):
item['weakness'].append(weakness.css('a span::text').get().strip())
yield item
for next_page in response.css('.pokedex-pokemon-pagination a.next'):
yield response.follow(next_page, self.parse)
Wenn alle Felder befüllt sind, übergeben wir das Pokémon mit yield an die Item-Pipeline. Danach schicken wir den Scraper mit der Funktion follow zum nächsten Eintrag, und dieser führt dort dann wieder die parse Funktion aus.
Pokémon lagern
Da unser Scraper nun eigenständig den offiziellen Pokédex durchkämmt, müssen wir uns jetzt noch Gedanken machen wie wir diese Daten verarbeiten und speichern. Mit Scrapy wird diese Aufgabe meist über Pipelines gelöst, welche die Items durchlaufen nachdem sie von einem Scraper gefunden wurden. Eine Pipeline besteht grundlegend aus den drei Funktionen:
- open_spider: Initialisierung der Pipeline, wenn der Scraper gestartet wird.
- close_spider: Aufräumen, nachdem der Scraper beendet wurde.
- process_item: Die Verarbeitung der einzelnen Items.
Für unseren Scraper schreiben wir eine einfache Pipeline, die alle Einträge aus dem Pókedex in eine leicht zu verarbeitende JSON-Datei speichert:
class PokePipeline(object):
def open_spider(self, spider):
self.file = open('../pokedex.json', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
Danach müssen wir unsere Pipeline noch beim Scraper registrieren, dazu erweitern wir die Klasse PokeSpider um die Variable custom_settings:
class PokeSpider(Spider):
name = 'pokeSpider'
start_urls = [
'https://www.pokemon.com/de/pokedex/001'
]
custom_settings = {
'ITEM_PIPELINES': {
'scrapeThemAll.PokePipeline': 400
}
}
Ab ins hohe Gras!
 Damit ist unser Scraper fertig und wir können anfangen das hohe Gras zu durchstreifen. Scrapy Scraper werden normalerweise über die Konsole gestartet, oft klappt das aber auf Windows-Systemen nicht, da die PATH-Variable falsch konfiguriert ist. Deshalb machen wir unsere Datei scrapeThemAll.py direkt ausführbar, damit können wir den Scraper später mit dem Befehl
Damit ist unser Scraper fertig und wir können anfangen das hohe Gras zu durchstreifen. Scrapy Scraper werden normalerweise über die Konsole gestartet, oft klappt das aber auf Windows-Systemen nicht, da die PATH-Variable falsch konfiguriert ist. Deshalb machen wir unsere Datei scrapeThemAll.py direkt ausführbar, damit können wir den Scraper später mit dem Befehl $ python scrapeThemAll.py. Um scrapeThemAll.py direkt ausführbar zu machen müssen wir unserem Code nur die für Python-Skripte bekannte Abfrage if __name__ == '__main__': anfügen. Damit sollte unserer Datei wie folgt aussehen:
import json
from scrapy import Spider
from scrapy.item import Item, Field
from scrapy.crawler import CrawlerProcess
class Pokemon(Item):
name = Field()
number = Field()
type = Field()
weakness = Field()
evolution = Field()
class PokeSpider(Spider):
name = 'pokeSpider'
start_urls = [
'https://www.pokemon.com/de/pokedex/001'
]
custom_settings = {
'ITEM_PIPELINES': {
'scrapeThemAll.PokePipeline': 400
}
}
def parse(self, response):
item = Pokemon()
item['name'] = response.css('.pokedex-pokemon-pagination-title div::text').get().strip()
item['number'] = response.css('.pokedex-pokemon-pagination-title .pokemon-number::text').get().strip()[3:]
item['type'] = []
item['weakness'] = []
for type in response.css('.pokedex-pokemon-attributes.active .dtm-type li'):
item['type'].append(type.css('a ::text').get())
for weakness in response.css('.pokedex-pokemon-attributes.active .dtm-weaknesses li'):
item['weakness'].append(weakness.css('a span::text').get().strip())
yield item
for next_page in response.css('.pokedex-pokemon-pagination a.next'):
yield response.follow(next_page, self.parse)
class PokePipeline(object):
def open_spider(self, spider):
self.file = open('../pokedex.json', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
if __name__ == '__main__':
crawler = CrawlerProcess()
crawler.crawl(PokeSpider)
crawler.start()
Scrape mit Respekt!

Screenshot: Pokémon: Let´s Go, Pikachu!
- Beachtet die Regeln der robots.txt.
- Überlastet nicht die Server eines Seitenbetreibers.
- Identifiziert euren Scraper mit einem Aussagekräftigen Useragent.
- Nervt nicht die System Administratoren einer Webseite.
Das könnte Dich auch interessieren

Prokrastination vs. Prekrastination: Was macht mir Stress bei der Arbeit?
Prokrastination und Prekrastination sind wie die zwei Seiten derselben Medaille, nämlich der Medaille eines Menschen, dessen Arbeitsprozesse nicht optimal lauf...

Maybe we should just take a break
Neben der Arbeit die ihr täglich erbringt, ist es genauso wichtig, dass ihr euch ab und zu eine Pause gönnt. Warum eine kurze Pause so wichtig ist und wie ihr...

Urlaubsplanung mit ChatGPT – Ab in den Urlaub #2 – Jetzt erst recht!
Die Reise mit dem Hovercraft nach Island war ja schön und gut, aber Island ist mir etwas zu klein, um mit meinem Hovercraft hinüberweg zu düsen. Also…. auf...